-
Linked List (연결 리스트)자료구조 2020. 5. 6. 01:04
Linked List ( 연결 리스트 )
연결 리스트는 그 크기가 동적인 자료구조로, 자료구조를 구성하는 요소( Node )노드의 연결로 이루어진 자료구조 입니다.
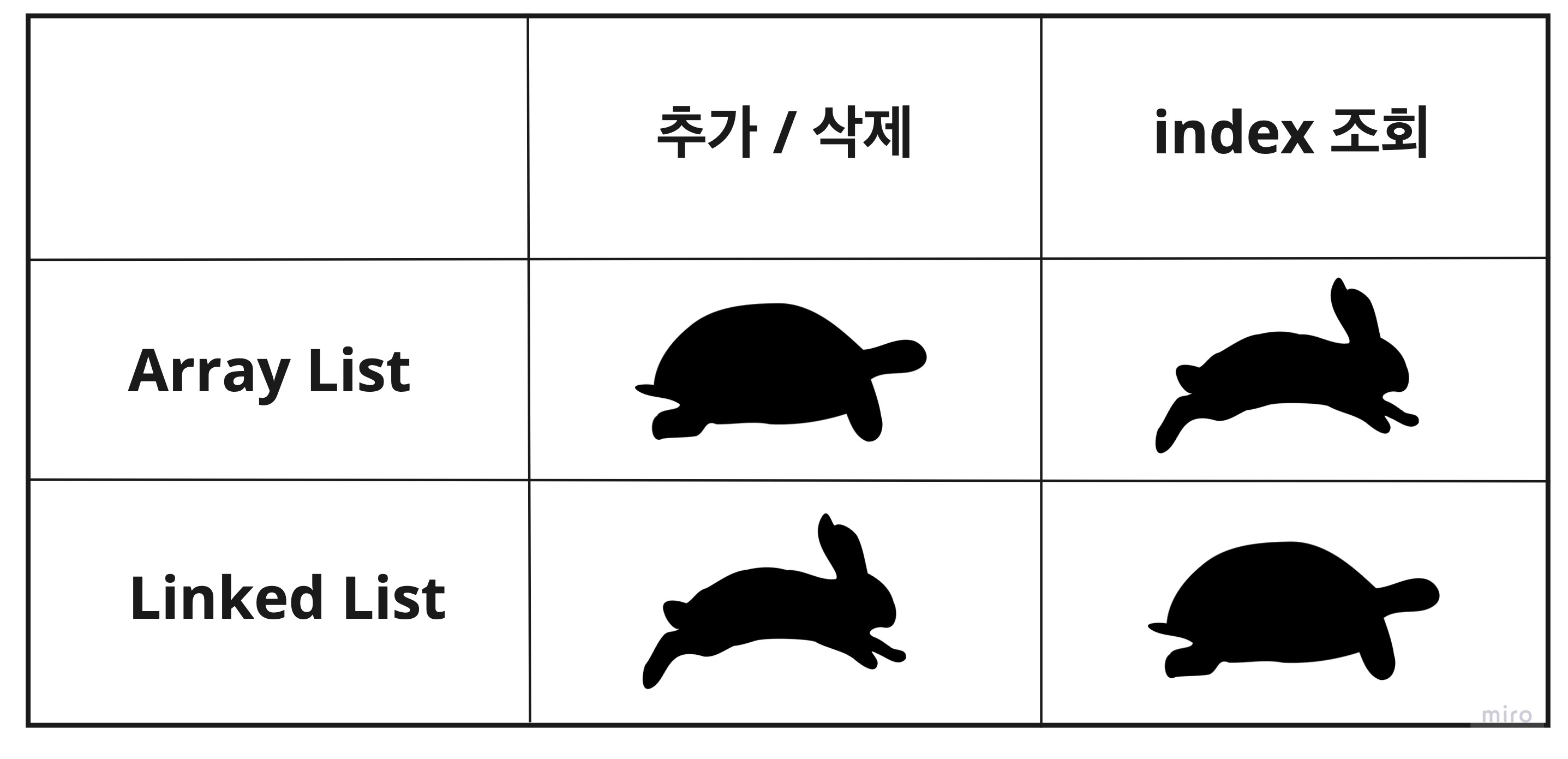
연결리스트의 어떠한 임의의 지점에 데이터의 추가와 삭제를 할 경우, O(1) (상수 시간)의 시간 복잡도를 갖습니다.
추가와 삭제에 대해 O(n) (선형 시간)의 복잡도를 갖는 배열과는 다릅니다.
다만 이 추가와 삭제 속도에 대한 대가로, 연결 리스트의 각 노드는 인덱스를 갖지 않습니다. 그래서 어떤 특정 데이터를 연결 리스트에서 검색하고자 할 경우, 처음부터 전체 연결 리스트를 훓어야 하며, 이는 O(n) (선형 시간)의 복잡도를 필요로 합니다.
따라서 Linked List는 그 위치들이 각각 흩어져 있기 때문에 서로 연결되어 있어야 합니다. 바로 그런 점에서 연결이라는 이름을 갖게 된 것입니다.
Linked List의 구조
리스트는 노드들의 모임입니다. 내부적으로 각각 노드를 가지고 있다는 것입니다. 배열리스트의 경우에는 배열의 내부적으로 각각의 엘리먼트를 가지고 있었는데 Linked List 는 배열 대신에 다른 구조를 사용합니다.
노드는 최소한 두 가지의 정보를 알고 있어야 합니다. 노드의 값(value)과 다음 노드(next)입니다. 각각의 노드가 다음 노드를 알고 있기 때문에 하나의 연결된 값의 모임을 만들 수 있는 것입니다.
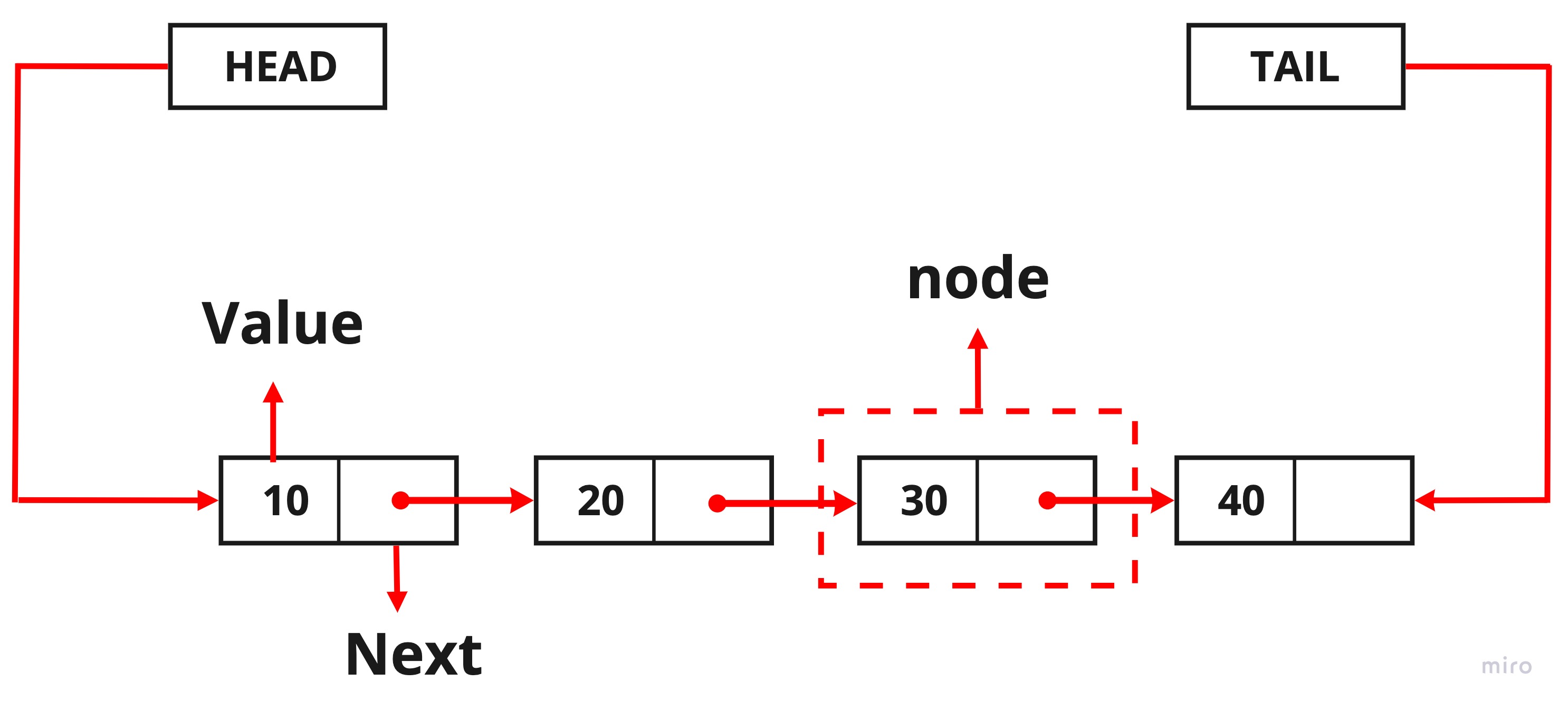
Linked List 이미지 위의 사진처럼 head는 항상 첫 번째 노드를 가리키고 있고 tail은 항상 마지막 노드를 가리키고 있습니다.
각각의 노드에는 value와 next가 있고 value에는 노드의 값이 저장되고, next에는 다음 노드의 참조 값을 저장해서 노드와 노드를 연결시키고 있는 것을 알 수 있습니다.
데이터를 시작 부분에 추가하기
다음과 같은 노드가 있습니다.
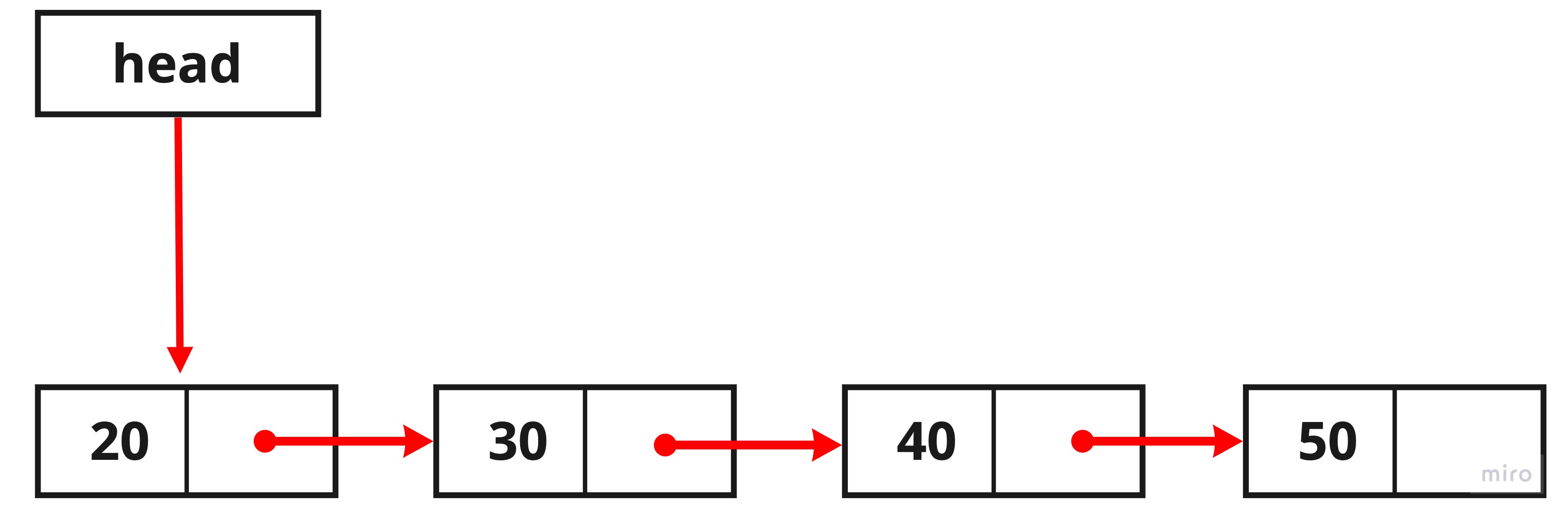
위의 노드에서 현재 head는 value20을 가지고 있는 노드를 가리키고 있습니다.
새로운 노드를 생성하여 첫 번째 위치에 추가하려는 작업을 하려면 아래와 같은 절차로 진행 될 것입니다.
new Node()로 생성될 객체를 만들기 위한 class 생성자가 있습니다.
class Node { constructor(value) { this.value = value; this.next = null; } }1. new Node()로 새로운 노드를 생성합니다.
let temp = new Node(value);
2. 새로 생성한 노드의 next가 첫 번째 노드를 가리키게 하기
temp.next = this.head;
현재 this.head의 값은 value값이 20인 노드를 가리키고 있습니다.
따라서 new Node()로 새로 생성한 노드(temp)의 next가 현재 head가 가리키고 있는 첫 번째 노드를 가리키게 되었습니다.
3. 새로 생성된 노드가 head가 가리키고 있는 첫 번째 노드가 되도록 head의 값 변경하기
this.head = temp;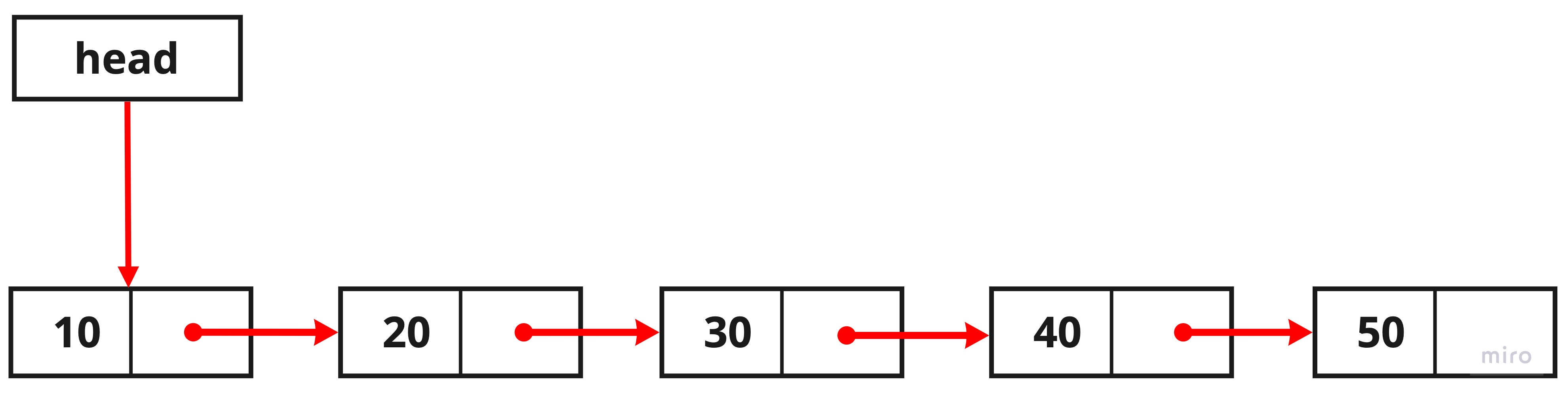
this.head가 원래는 value값이 20인 노드를 가리키고 있었는데, this.head = temp;로 새로 생성된 temp노드를 할당해 줌으로써 현재 head 값이 바뀐 것을 볼 수 있습니다.
위의 작업에 대한 전체 코드를 정리해 보자면 다음과 같습니다.
// 새로운 노드 생성 let temp = new Node(10); // 새로운 노드의 다음노드로 현재 첫 번째 노드를 가리키고 있는 head 연결 temp.next = this.head; // 항상 첫 번째 노드를 가리키고 있을 head에 새로 생성한 노드를 연결해주기 this.head = temp;새로운 노드를 중간에 추가하기
아래의 그림과 같이 index 2 번째에 새로운 노드를 추가하는 방법에 대해 알아보겠습니다.
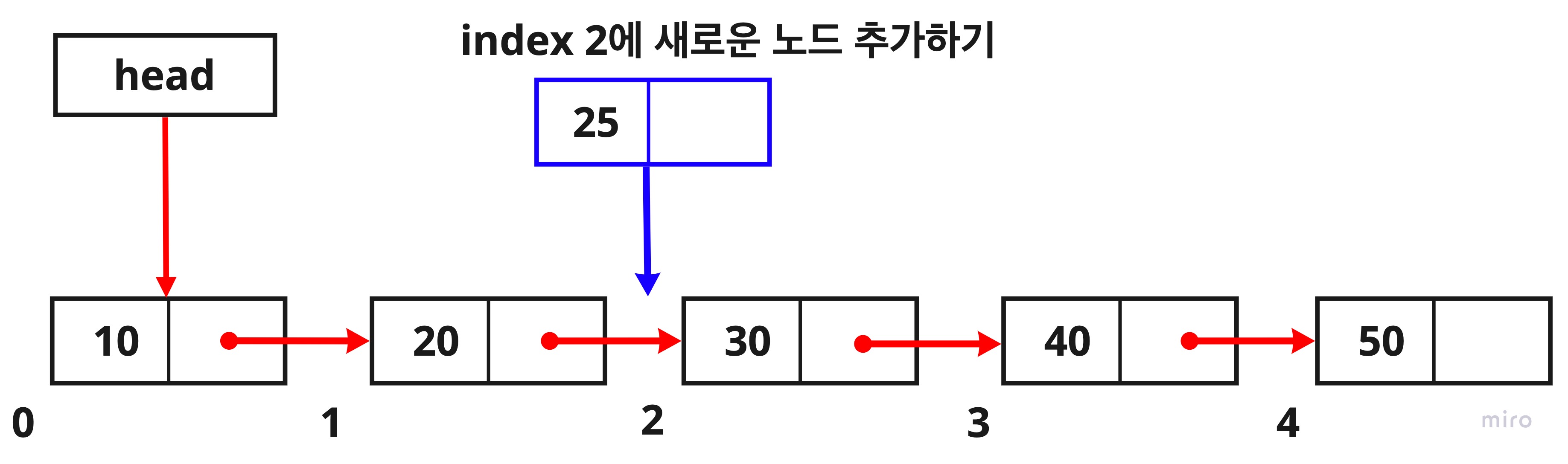
1. 현재의 head를 참조하여 첫 번째 노드 찾기
let temp1 = this.head;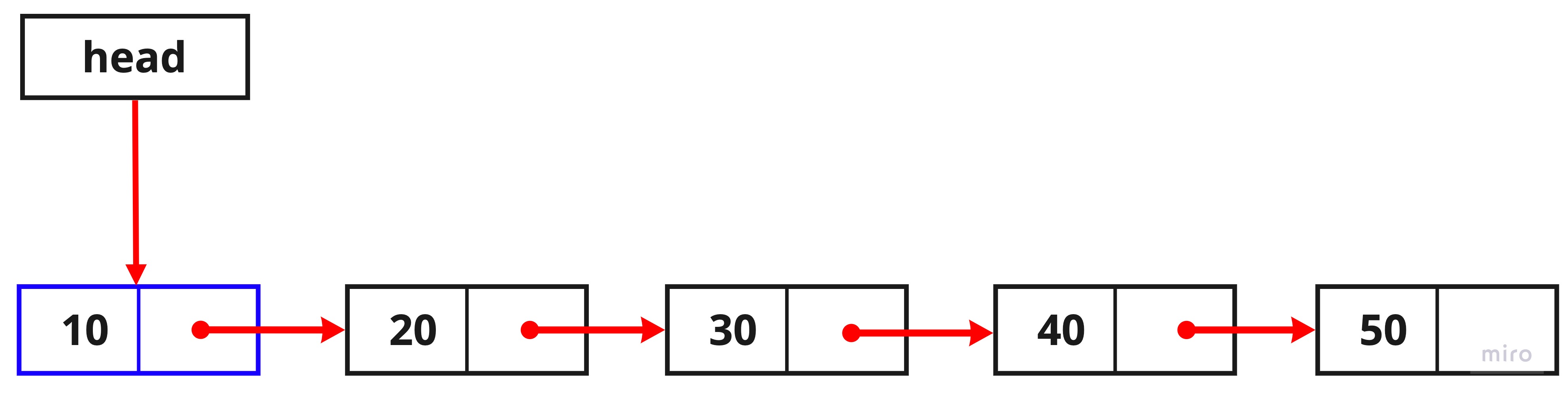
head는 항상 첫 번째 노드를 가리키고 있으므로 this.head를 찾아 변수 temp1에 담아주었습니다.
2. index2번째 자리에 새로운 노드를 위치 시키기 위해 value값이 20인 노드 찾아오기
while(--k !== 0){ temp1 = temp1.next; }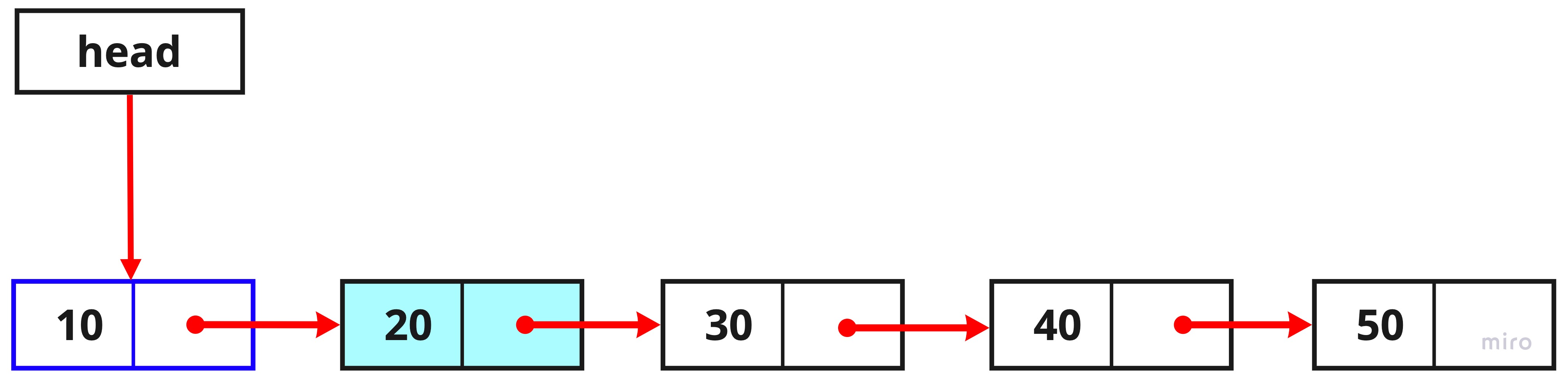
while문 안에 있는 k는 현재 내가 추가 하고싶은 index값인 2를 의미합니다.
while문으로 --k !== 0 이라는 조건문을 넣어주었는데 이 조건문은 증감 연산자인 --으로 k를 하나씩 감소시키고 감소 된 값이 0과 같지 않을 때까지 반복문을 실행시킵니다.
k에 2가 들어가고 첫 반복문에서 --1 !== 0 이 참이므로 temp1에 temp1의 next를 할당하고, 다음 반복문을 실행할 때에는 k가 0이 되어 조건문에 통과하지 못하기 때문에 temp1의 값은 value가 20인 노드가 되는 것입니다.
이렇게 해서 추가하고자 하는 index의 이 전 노드를 알 수 있게 되었습니다.
이제 추가하고자 하는 index의 다음 노드를 가져와야 합니다.
3. 2번에서 찾아온 노드를 이용하여 추가하고자 하는 index의 다음 노드 찾아오기
let temp2 = temp1.next;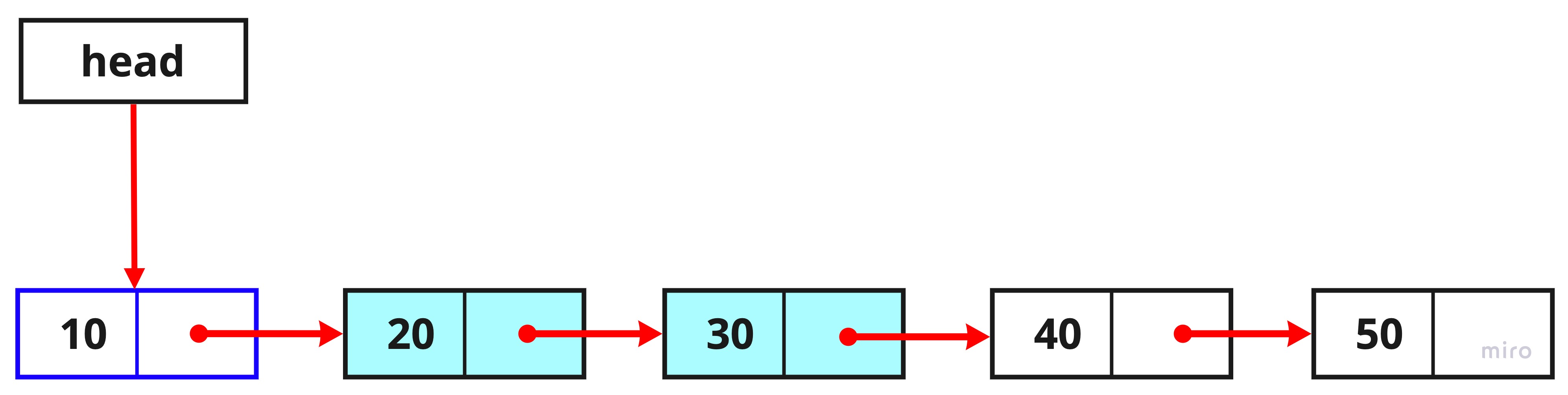
temp1에는 현재 value가 20인 노드를 담고 있습니다.
temp1의 next는 value가 30인 노드를 연결하고 있으므로 temp1.next로 추가하고자 하는 index의 다음노드를 알 수 있습니다.
4. 추가할 새로운 노드 생성하기
let newTemp = new Node(25);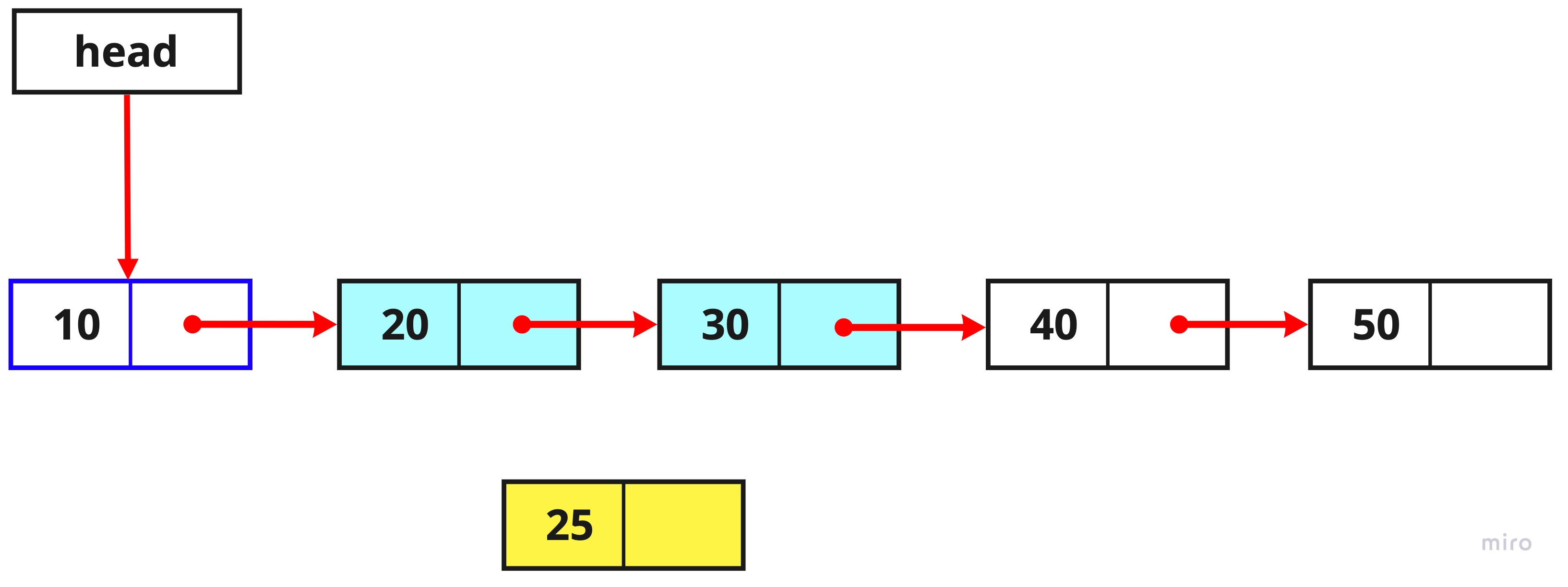
5. value가 20인 노드의 next 노드로 새로운 노드를 지정합니다.
temp1.next = newTemp;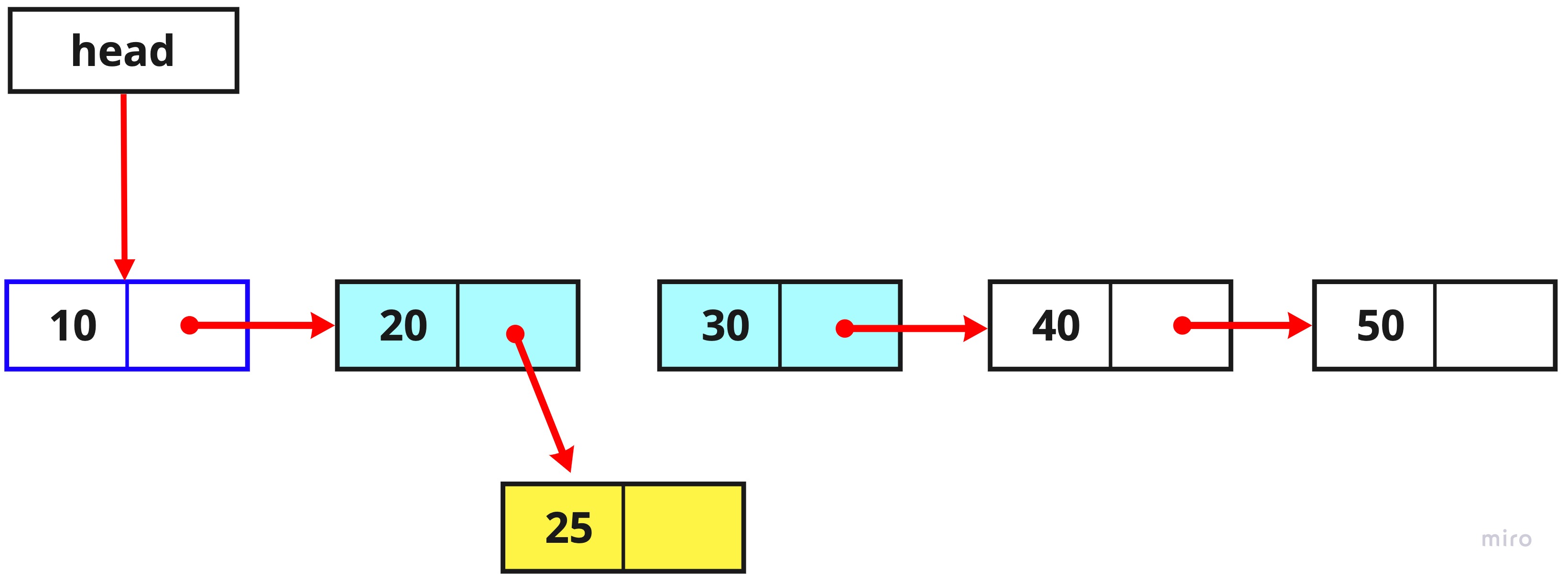
6. 새로 생성한 노드의 next 노드로 value가 30인 노드를 연결합니다.
newTemp.next = temp2;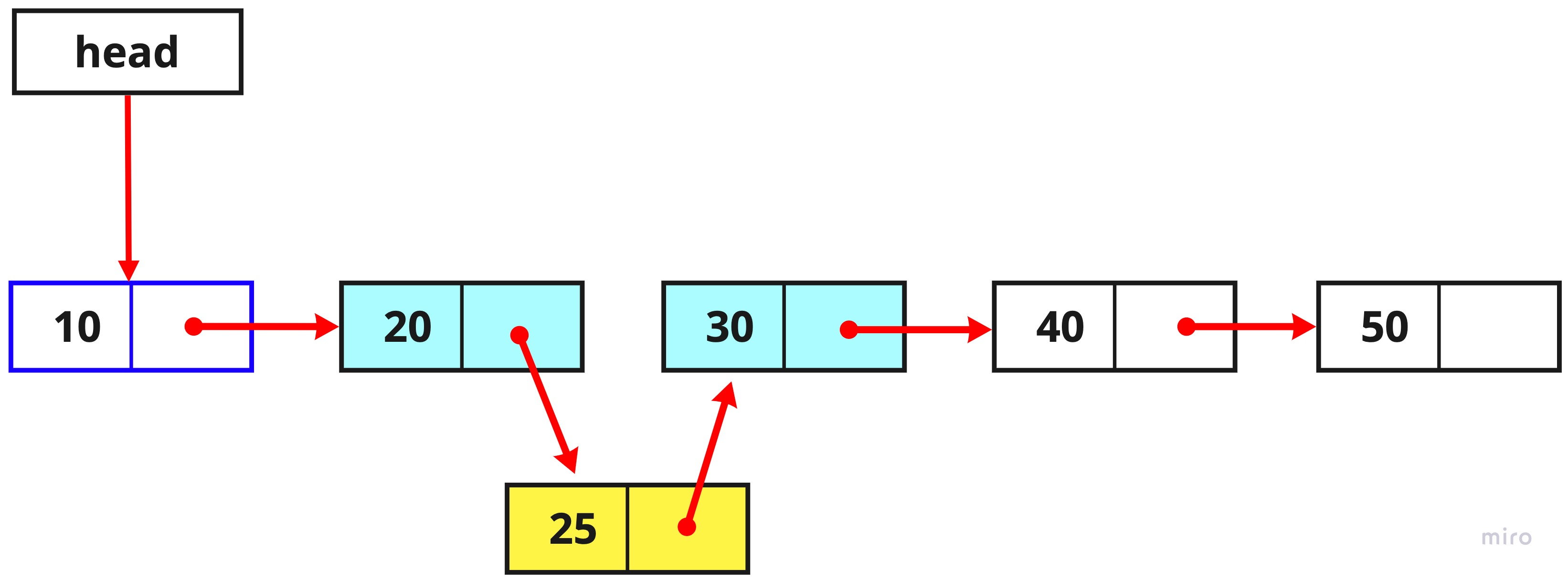
7. 새로운 노드가 추가된 최종적인 Linked List
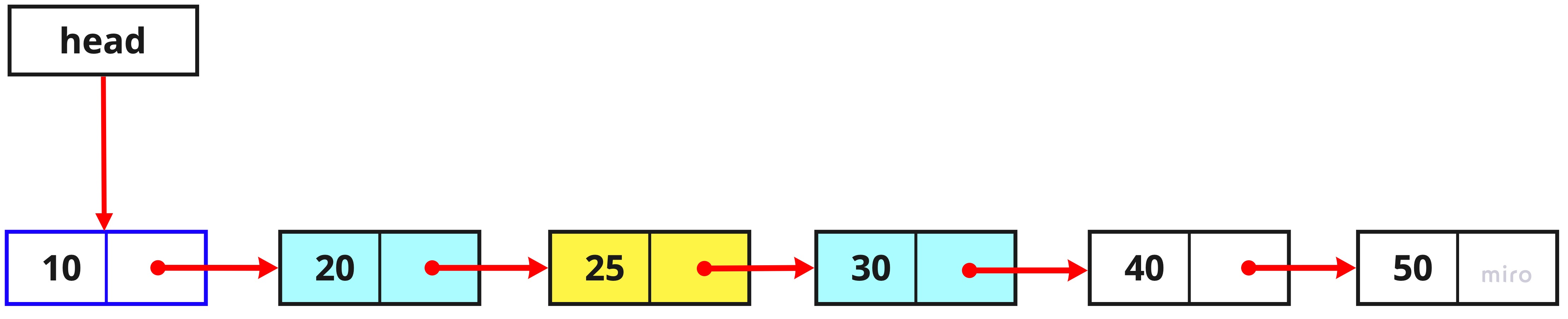
이렇게 해서 index2 번째에 새로운 노드를 생성하여 추가해보았습니다.
중간에 새로운 노드를 추가하기 위해서 while문을 사용하여 index 값을 알 수 있었습니다.
※ 중간에 데이터를 추가/삭제 하는 과정에서 배열과 Linked List의 차이점
배열의 경우에는 중간에 추가/삭제할 경우 해당 엘리먼트의 뒤에 있는 모든 엘리먼트의 자리 이동이 필요했습니다.
모든 엘리먼트를 한 칸씩 뒤로 이동하여 추가하고자 하는 값의 자리를 만들어 주어야 했기 때문입니다.
반대로 Linked List 의 경우 추가/삭제가 될 노드의 이전, 이후 노드의 참조 값(next)만 변경하면 되기 때문에 배열보다 더 빠릅니다.
즉, 추가/삭제의 과정에서 배열은 모든 엘리먼트를 한 칸씩 뒤로 이동하여야 하는 반면, Linked List는 앞, 뒤 노드의 참조 값만 변경하면 된다는 차이점이 있습니다.
하지만 또 다르게 보면 이 노드들이 몇 백개가 존재하고 있다면 해당하는 index 값을 찾기 위해서 첫 번째의 노드부터 하나씩 검사해 나가야 한다는 점에서는 배열보다 Linked List가 훨씬 더 비효율적이고 느릴 수 있을 것같습니다. (시간 복잡도)
이 부분에 대해서는 아래에 index를 이용하여 데이터 조회하는 방법에 대한 과정에서 더 알아보겠습니다.
위의 작업에 대한 전체 코드를 정리해 보자면 다음과 같습니다.
// 현재 첫 번째 노드 가져오기 let temp1 = this.head; // 반복문을 통해 이전 노드 가져오기 while(--k !== 0){ temp1 = temp1.next; } // 찾아온 이전 노드의 next를 통해 다음 노드 가져오기 let temp2 = temp1.next; // 새로운 노드 생성 let newTemp = new Node(); // 이전 노드의 next에 새로운 노드 연결 temp1.next = newTemp; // 새로운 노드의 next에 찾아온 다음 노드 연결 newTemp.next = temp2;노드 삭제하기
노드를 제거하는 것도 추가하는 것과 비슷합니다.
위의 설명에서 노드를 추가할 때 이 Linked List의 size에 관해서 따로 설명하지 않았는데 이번 노드 삭제를 알아볼 때에는 size를 사용할 것입니다. size는 this.head 와 같이 사용할 수 있으며 노드를 추가할 때마다 코드의 맨 앞에 this.size++; 을 해줌으로써 추가 될 때마다 size를 늘려주는 것입니다. 만약 노드가 5개가 존재하고 있다면 size는 5가 될 것입니다.
아래 그림의 리스트에서 세 번째 노드(index 2)를 제거하는 과정을 알아보겠습니다.
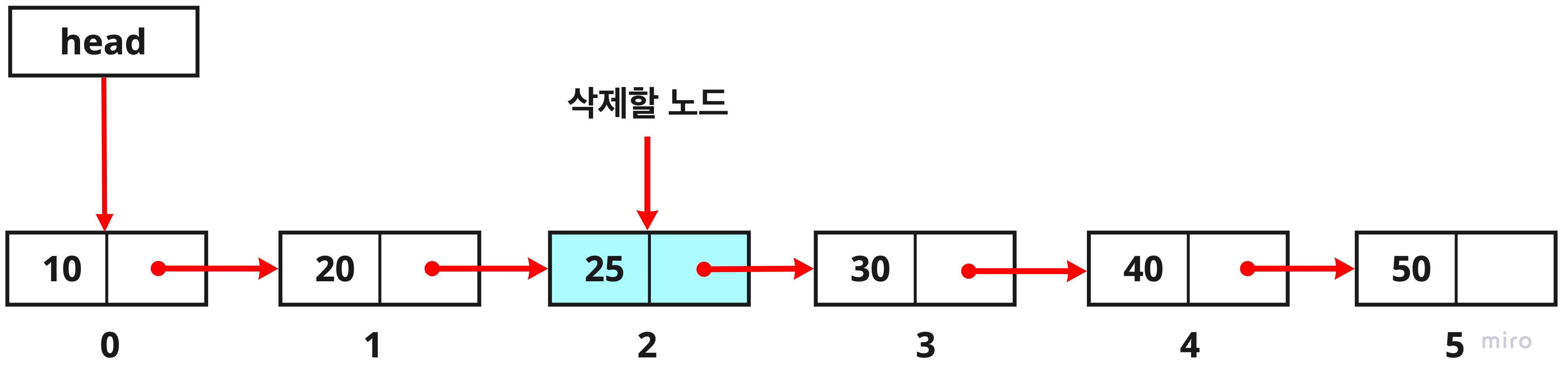
1. head를 통해 첫 번째 노드를 찾습니다.
let current = this.head;
2. 첫 번째 노드를 담은 current를 통해 두 번째 노드를 찾습니다.
while(--k !== 0){ current = current.next; }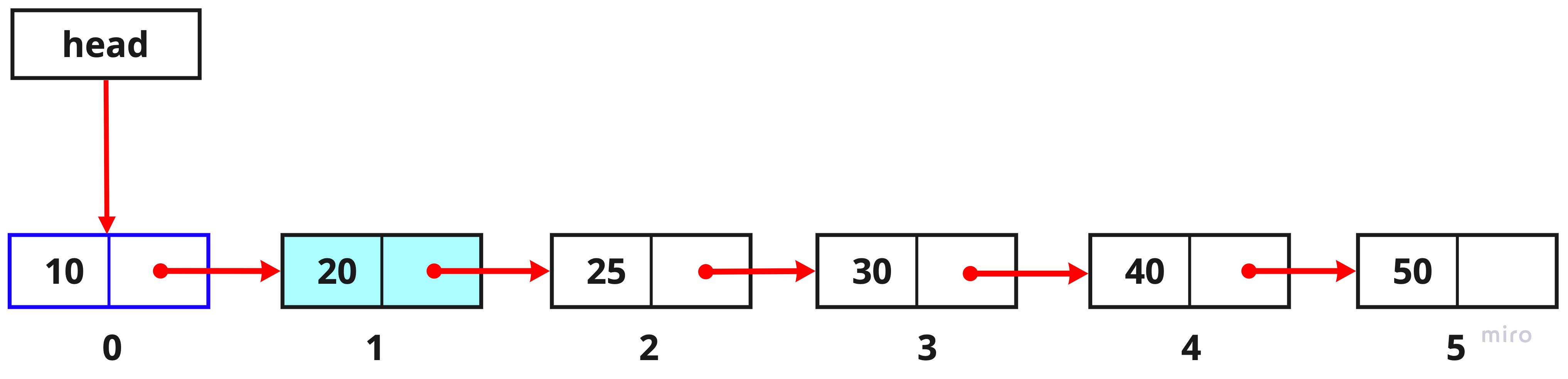
중간에 노드를 추가할 때 처럼 while문을 사용하였고 while문 안에 있는 k는 찾고자하는 index 번호입니다. 즉, 여기에서는 2가 된 것이고 이 index 를 --k로 감소시키면서 다음 노드를 찾기 위해 current에 current.next 노드를 할당하는 것입니다.
3. 세번째 노드를 찾았습니다.
let tobeDeleted = current.next;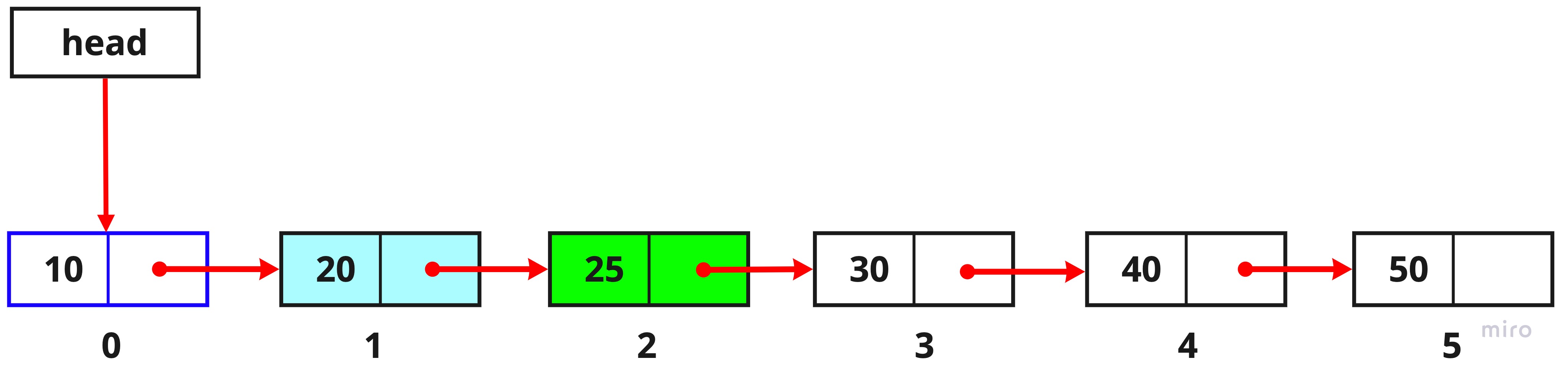
2번에서 찾아온 두 번째 노드의 next를 통해 우리가 삭제하고자 했던 index 2번의 노드를 찾습니다.
4. 두 번째 노드의 next를 index가 3인 노드로 변경합니다.
current.next = current.next.next;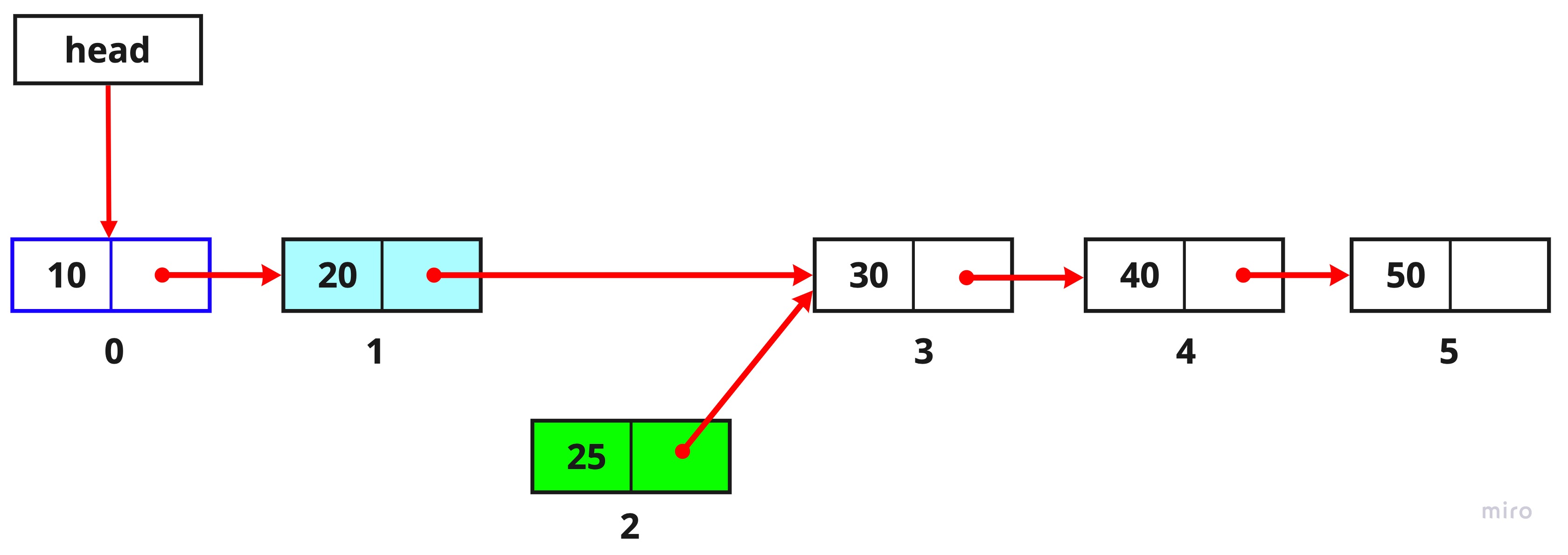
index가 2번째인 노드였던 current.next를 current.next.next로 indexrk 3인 노드에 연결시켜 주었습니다.
current.next는 index가 2인 노드이기 때문에 .next로 한번 더 거쳐서 그 다음 노드로 이동하는 것입니다.
지금은 index가 1인 노드와 index가 2인 노드가 index가 3인 노드를 같이 바라보고 있으므로 List의 size를 줄여서 이 연결을 해제시켜 주면 됩니다.
5. Linked List의 size를 감소시켜 노드의 연결 끊기
this.size--;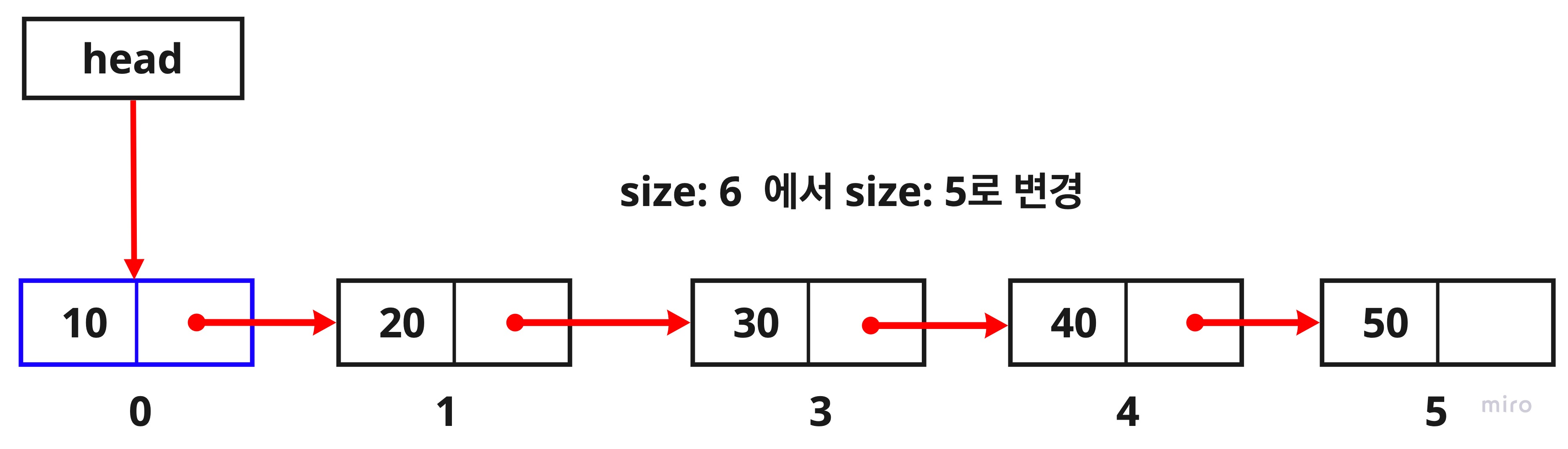
원래는 이 노드들을 추가하면서 this.size++;을 통해 늘어났을 size가 6이었는데 노드를 삭제하면서 this.size--;를 통해 전체적인 size가 줄어들었습니다. size가 줄어들면서 삭제하고자 했던 노드의 연결이 끊어졌습니다.
index를 이용한 노드 조회
index를 이용해서 노드를 조회할 때 Linked List는 head가 가리키는 첫 노드부터 시작해서 순차적으로 노드를 찾아가는 과정을 거쳐야 합니다. 만약 찾고자하는 노드가 가장 끝에(tail) 있다면 모든 노드를 탐색해야 하는 것입니다.
let index = 0; let current = this.head; // 찾고자 하는 value값이 this.head의 value값과 같지 않고 현재 this.head가 맨 마지막인 this.tail과 같지 않을 때까지 반복문을 돌립니다. while (current.value !== value && current !== this.tail) { index++; current = current.next; } return current.value === value ? index;이 처럼 Linked List에는 index가 존재하지 않기 때문에 index를 셀 수 있는 변수를 하나 만들고, this.head를 current라는 변수에 담아줍니다. while 문을 통해서 찾고자 하는 value값이 this.head의 value값과 같지 않고 현재 this.head가 맨 마지막인 this.tail과 같지 않을 때까지 반복문을 돌립니다. 반복문이 한번 돌아가고 나면 index++; 을 통해 index를 하나씩 증가 시켜주고 current변수에 current.next 노드를 계속해서 넣어줍니다.
찾고자 하는 인덱스까지 도달하게 되면 return문으로 current.value === value와 같다면 해당하는 노드의 index를 반환하면 됩니다.
노드의 index가 아닌 value를 반환하고 싶다면 return current.value로 반환해주면 됩니다.
위에서 알아본 것처럼 Linked List에서는 찾고자 하는 노드를 발견할 때까지 처음부터 순차적으로 노드를 찾아가는 과정을 거쳐야 합니다.
반면에 배열을 이용해서 리스트를 구현한 것은 배열의 인덱스를 이용하여 해당 엘리먼트에 바로 접근 할 수 있기 때문에 매우 빠릅니다.
Linked List에서의 노드 조회

배열에서의 엘리먼트 조회

trade off
트레이드 오프는 어떤 특성이 좋아지면 다른 특성이 나빠지는 상황을 의미한다고 합니다. 배열리스트와 Linked List는 트레이드 오프의 좋은 사례라고 할 수 있습니다. 자료구조를 배우는 이유 중의 하나는 이러한 트레이드 오프를 이해하기 위해서 인 것 같습니다.
장점과 단점의 미묘한 균형을 이해할 수 있어야 더 나은 선택을 할 수 있기 때문입니다.
따라서 위에서 알아본 내용들을 종합해서 보여주는 그림은 다음과 같습니다.
'자료구조' 카테고리의 다른 글
Tree와 Binary Search Tree (0) 2021.02.26 Hash Table (해시 테이블) (0) 2021.01.28 Graph 자료구조 (0) 2020.05.07 Stack & Queue (0) 2020.05.03